
It's the Harness, Not the Model
Why the scaffolding around an AI model matters more than the model you pick.


I first heard the phrase harness engineering on a monthly peer call with other people working on AI in investing. It came up again, more prominently, at the AI Engineer Europe conference I went to two months ago, and that was the moment it clicked for me. Since then I keep noticing how many investors are still stuck firing one-shot prompts at a chat window.
Most of my conversations with investment teams open the same way: which model is best right now, and how on earth do you keep up when the leader changes every month. Claude, GPT, Gemini, the top of the leaderboard never sits still for long.
It is the wrong thing to fixate on. The model still matters, but the gap between the frontier providers is narrowing, and it is no longer where the real difference is made. That comes from what you wrap around the model: the tools it can use, the data it can reach, the memory it carries from one session to the next. This is the harness. Most people are studying the engine specs and ignoring the rest of the car.
So this is a short guide, written for investment teams, on harnesses and why they matter more than the model you pick.
What I mean by the harness
Think of the model as the raw reasoning engine. On its own it is a brilliant analyst who walks in every morning with no memory of the day before. CFA-level intelligence, genuinely, but no access to your systems, no sight of your data, and no recollection of anything you asked yesterday.
The harness is everything you build around that analyst to turn raw intelligence into useful work: the connections into your data, the tools they can reach for, the repeatable processes they follow, and the checks that catch mistakes before anyone acts. Same analyst, completely different output depending on what surrounds them.
The evidence is hiding in plain sight
The cleanest proof comes from software engineering, where people measure this properly. SWE-bench asks an AI to fix real bugs in real codebases, and it has become the standard test of how good these systems are at doing actual work.
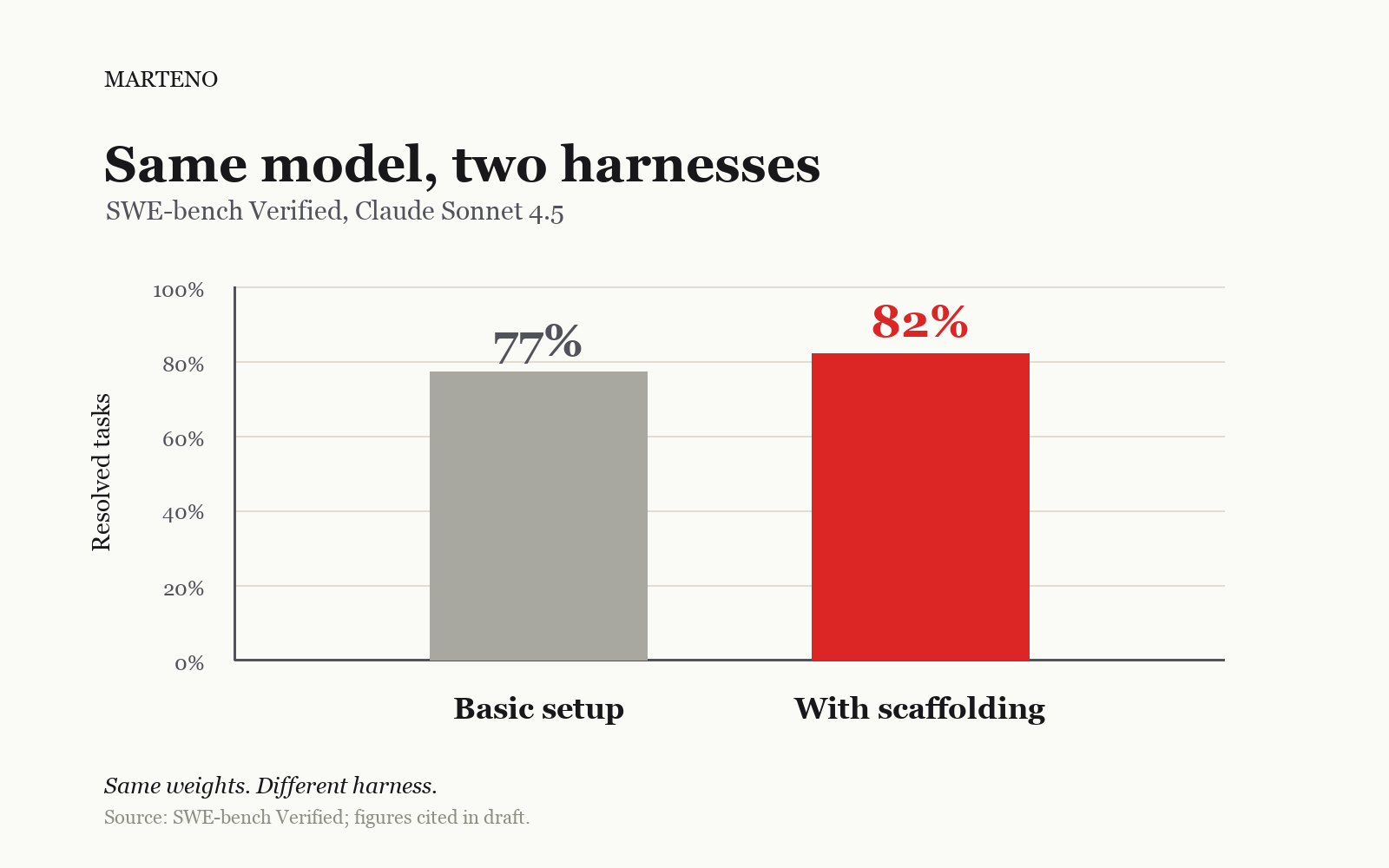
Here is the part investors should sit up for. Take one model, Claude Sonnet 4.5, on a fixed set of problems. With a basic setup it solves around 77 per cent. Give it a better harness, one that lets it attempt a problem several ways and check its own answers, and the same model jumps to 82 per cent. The model did not change. Only the harness around it did.
It goes further. An open-source harness called mini-SWE-agent is barely a hundred lines of code, yet paired with a frontier model it clears 74 per cent, holding its own against far heavier and more expensive systems. A hundred lines of the right wiring closes most of the gap.
None of these benchmarks are perfect, and the labs have every incentive to flatter their own numbers. But the pattern holds: the same model, placed in different harnesses, produces meaningfully different results. The spread between harnesses is doing more work than the spread between models.
What this looks like away from the benchmark
I have watched this play out in real investment work this year. Over the past few weeks I have been sitting one-to-one with a hedge fund CIO, using a Claude-based harness to build out actual research workflows. What made it work was never the model underneath. It was that the harness let us connect to the right data, encode the process once, and refine it run after run until the output was something a PM would genuinely trust.
My own setup tells the same story. I do nearly all my building in Claude Code, not because its model is special, but because the harness around it lets me wire in my own data, reuse my own processes, and carry memory across sessions. I moved to it from an ordinary chat window running a comparable model, and the work got noticeably better. The model I happened to pick mattered far less than the rig around it.
The part investors should care about most: connectors

If the harness is where the value sits, the question that really matters is what your harness is plugged into.
This is where it gets interesting for our industry. Data providers are starting to ship their feeds in a form a harness can connect to directly, through an emerging standard called MCP. I have been working with several fintech startups on exactly this, and across every conversation the direction is the same: providers are building connectors so their data flows straight into the model’s harness, rather than being copied and pasted in by hand.
It matters because a brilliant model connected to nothing is just an analyst locked in a room with no phone and no Bloomberg. The edge was never the model. The edge is what you have plumbed into it.
The honest limitation
None of this solves the underlying problem. A better harness makes the model more capable and far better connected, but it does not make it correct. It will still hand you confident, beautifully formatted answers that are simply wrong, and once it is wired into live data it can be wrong faster and more plausibly than before.
So the discipline does not disappear, it moves. You have to carve out real time to test the output on companies you already know inside out, precisely so you can catch the hallucinations and the quiet errors. Assume from the start that there will be inaccuracies, and design the process so a human sees them before anyone acts on them. A harness earns trust through repeated runs, not through a good demo.
Where this is going
Both layers are improving at once. The models keep getting more capable, and the harnesses around them are maturing quickly, with better tools, better memory, and a fast-growing set of data connectors. The gap between a team poking at a raw chat window and a team running a properly wired harness is going to widen, not close.
I’ll share more on the practical side in future issues.
-Jeremy